우아한 형제들에서 코로나로 인해서 2020 우아콘을 온라인으로 진행햇었던것을 보고 내용이 너무 좋아서 정리해놓으면 좋을거 같다고 생각했습니다.
주제는 적제된 데이터가 1000만건에서 10억건까지 되는 과정에서 얻은 Querydsl-JPA 개선 팁입니다.
테스트 환경으로
java(OpenJDK 1.8.0_252)
Querydsl(Querydls-JPA 4.2.1)
Database(AWS Aurora MySQL 5.6 1.19.6)
MySQL 5.6 -> 인덱스 컨디션 푸시다운과 서브쿼리의 최적화
QueryDSL -> 버젼별 문법 변화
Querydsl은 버전에 따라서 문법이 변화하는 경우가 많아서 버전체크가 중요합니다.
- 4.0.1 버전까지는 list 조회 시 .list() 메서드를 사용
- 4.0.2 버전부터는 fetch() 메서드로 이름이 변경됨
- 등 많음
www.querydsl.com/static/querydsl/4.2.1/reference/html_single/ - 4.2.1 공식 문서
(저도 아직 공식문서를 보지않았는데 한번 시간 내서 봐야겠습니다.)
1.워밍업
1. extends / implement 사용하지 않기

커스텀을 위해서 해야하는 일은 다음과 같습니다.
1. 커스텀 인터페이스를 만들어서 메서드 선언
public interface MemberRepositoryCustom {
List<MemberTeamDto> search(MemberSearchCondition condition);
Page<MemberTeamDto> searchPageSimple(MemberSearchCondition condition, Pageable pageable);
Page<MemberTeamDto> searchPageComplex(MemberSearchCondition condition, Pageable pageable);
}
2. 커스텀 인터페이스를 구현한 Impl 구현(클래스명이 강요됨 - jpa 저장소 클래스 이름 뒤에 Impl)
public class MemberRepositoryImpl implements MemberRepositoryCustom {
private final JPAQueryFactory queryFactory;
public MemberRepositoryImpl(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
@Override
public List<MemberTeamDto> search(MemberSearchCondition condition) {
...
}
@Override
public Page<MemberTeamDto> searchPageSimple(MemberSearchCondition condition, Pageable pageable) {
...
}
// 쿼리와 카운트 쿼리를 분리
@Override
public Page<MemberTeamDto> searchPageComplex(MemberSearchCondition condition, Pageable pageable) {
...
}
}3. 저장소에 커스텀 인터페이스 extends
public interface MemberRepository extends JpaRepository<Member, Long>, MemberRepositoryCustom, QuerydslPredicateExecutor<Member> {
List<Member> findByUsername(String username);
}또는
매번 QuerydslRepositorySupport을 통해서 Support를 상속 받고 super 생성자에 Entitiy를 등록 하는 방법

상속/구현받지 않고 특정 엔티티를 지정하지않고 Querydsl을 사용할 수 있는방법
JPAQueryFactory를 생성자에 주입하여 사용하면 Querydsl의 모든 기능 사용 가능
@Repository
public class MemberJpaRepository {
private final JPAQueryFactory queryFactory;
public MemberJpaRepository(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
public List<Member> findByUsername_querydsl(String username) {
return queryFactory
.selectFrom(member)
.where(member.username.eq(username))
.fetch();
}
}
개인적인 생각
queryFactory로 구현하면 편리하지만 하나의 클래스에 집중될 수 있으니 적절하게 클래스를 분리해서 관리하기 용이하게 할 필요가 있을거 같다.
2. 동적쿼리
BooleanBuilder
동적 쿼리를 작성하기위해서 사용할 수 있지만 코드롤 보고 이해하기 어려움
public List<MemberTeamDto> searchByBuilder(MemberSearchCondition condition) {
BooleanBuilder builder = new BooleanBuilder();
if(hasText(condition.getUsername())){
builder.and(member.username.eq(condition.getUsername()));
}
if(hasText(condition.getTeamName())){
builder.and(team.name.eq(condition.getTeamName()));
}
if(condition.getAgeGoe() != null) {
builder.and(member.age.goe(condition.getAgeGoe()));
}
if(condition.getAgeLoe() != null) {
builder.and(member.age.loe(condition.getAgeLoe()));
}
return queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")
))
.from(member)
.leftJoin(member.team, team)
.where(builder)
.fetch();
}
BooleanExpression
null을 반환하면 조건에서 삭제되고 이해하기에도 편하다.

개인적인 생각
BooleanExpression은 null이 반환되는 부분에 대한 조건 체이닝이 안되고 모든 조건이 null이 발생하지않도록 신경 써야한다.
BooleanBuilder는 new BooleanBuilder를 생성한 뒤에 조건을 걸기 때문에 체이닝이 가능하고 BooleanExpression처럼 메서드를 따로 빼서 보기 좋게도 가능하긴 하다고 생각한다.
public List<MemberTeamDto> searchBetween(MemberSearchCondition condition) {
return queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")
))
.from(member)
.leftJoin(member.team, team)
.where(
betweenAge(condition.getAgeGoe(), condition.getAgeLoe())
)
.fetch();
}
// 체이닝
private BooleanBuilder betweenAge(Integer ageGoe, Integer ageLoe) {
return ageGoe(ageGoe).and(ageLoe(ageLoe));
}
private BooleanBuilder ageGoe(Integer ageGoe) {
return ageGoe != null ? new BooleanBuilder(member.age.goe(ageGoe)) : new BooleanBuilder();
}
private BooleanBuilder ageLoe(Integer ageLoe) {
return ageLoe != null ? new BooleanBuilder(member.age.loe(ageLoe)) : new BooleanBuilder();
}
2. 성능향상 - SELECT
1. Querydsl 에서 exists 메서드 사용 금지
SQL에서 exist의 경우 해당 조건을 찾으면 쿼리가 끝나지만 count는 끝까지 돌게 되서 exist는 권장되지만
Querydsl에서 exists메서드의 경우 count 쿼리가 나가됩니다.

조건에 해당하는 row 1개만 찾으면 바로 쿼리를 종료하는 쿼리를 직접 구현해야한다.

2. Cross Join 회피
cross join의 경우 모든 경우를 구하기 때문에 성능이 좋을수가 없다는 걸 다들 아실텐대 이를 위해서 명시적 조인을 통해서 해결해야한다.

3. Entity 보다는 Dto를 우선
entity - 실시간으로 변경이 필요한 경우
dto - 고강도 성능개선, 대량의 데이터 조회
조회 칼럼 최소화
이미 알고있는 칼럼의 경우 as를 통해서 조회하지않고 값을 셋팅 할수 있다.

select 칼럼에 엔티티 사용 자제
select 절에 엔티티를 조회하는 경우 대략 3가지의 문제가 발생한다고 볼 수 있다.
1. 해당 엔티티 전체를 조회하기 때문에 위의 칼럼 최소화와 같은 맥락에서 사용을 자제해야한다.

2. @OneToOne 관계의 경우 n+1이 무조건 발생하기 때문이다.
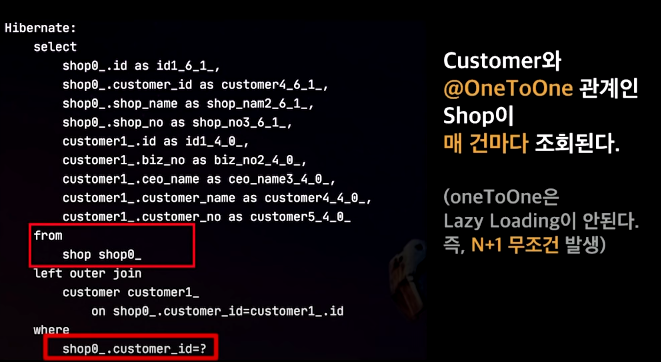
JPA에서는 OneToOne(이하 1:1)관계에서 무조건적인 LazyLoading(지연로딩)을 지원하지 않는다.
아래처럼 fetch 전략을 lazy로 설정하더라도 말이다.
@OneToOne(mappedBy = "delivery", fetch = FetchType.LAZY)
private Order order;JPA는 객체의 참조가 프록시 기반으로 동작하는데, 연관관계가 있는 객체는 참조를 할때 기본적으로 null이 아닌 프록시 객체를 반환한다.
1:1관계에서는 null이 허용되는 경우, 프록시형태로 null객체를 반환할 수가 없기 때문이다.
1:N관계는 이미 배열의 형태로 이미 참조할 프록시 객체를 싸고 있기 때문에 그 객체가 null이라도 참조할때는 문제가 되지 않는다.
따라서 JPA 구현체는 기본적으로 1:1관계에서는 지연로딩 를 허용하지 않고, 즉시 값을 읽어 들인다. 물론 Lazy를 설정할 수 있지만 특정조건을 모두 만족하지 않는다면 동작하지 않는다.
만약 위의 사진에서 customer - shop - ? 처럼 하나의 OneToOne관계가 있다면?

상상도 못한 수의 쿼리가 날라가게 된다. ㅎㄷㄷ
연관된 엔티티 저장에서 반대편 엔티티의 id값만 셋팅해서 해결할 수 있다.

3. distinct
select에 선언된 엔티티의 칼럼 전체가 distinct의 대상이 되면서 이를 위한 임시 테이블을 만드는 공간과 시간떼문에 성능이 떨어지게 된다.

개인적인 생각
OneToOne 관계에서 fetch전략을 설정하더라도 제대로 작동하지않을 수 있다는 사실을 처음알아서 적지 않아 당황했지만 lazy로딩의 방식인 프록시 관련해서 이해가 필수적이었다.
group by 최적화
mysql에서 group by를 실행했을때 index를 타지 않는 경우 filesort가 발생합니다.
이를 해결하기 위해서 mysql에서는 order by null을 사용해서 filesort를 제거하지만
Querydsl에서는 해당 문법을 지원하지 않는다.
그래서 아래와 같이 직접 구현해야한다.

추가적인 내용
정렬이 필요하더라도 조회 결과가 100 건 이하라면 애플리케이션에서 정렬을 추천
페이징일 경우order by null 사용 불가.
커버링 인덱스
커버링 인덱스 : 쿼리를 충족시키는데 필요한 모든 칼럼을 갖고 있는 인덱스

JPQL은 FROM절에 서브쿼리를 지원하지 않기 때문에 우회가 필요
커버링 인덱스 조회를 진행하고 이를 IN절을 통해서 후속 조회

3. 성능향상 - Update/Insert
update
jpa에서는 jpa persistence context에서 관리 중인 객체(하이버네이트 캐시)가 변경되면 DrityChecking에 의해서 자동으로 업데이트가 된다는 사실을 아실텐대 이 경우 쿼리가 1개씩 날라가기 때문에 만약 DrityChecking을 통해서 많은 수의 객체를 수정한다면 그 수만큼 쿼리가 날라가 성능이 떨어지게 된다.
이 경우 일괄 업데이트 문을 통해서 성능 향상이 가능하다. 다만 이경우 업데이트 문에 의한 변경은 jpa persistence context에 반영되지 않기 때문에 해당 값들을 맞춰줘야한다.
보통 맞춰주는 작업은 업데이트 문을 되도록 먼저 실행시키고 영속성 컨테스트를 초기화하는 방법이 있다.

bulk insert

bulk insert를 jpa를 통해서 하면 성능이 많이 떨어지기 때문에 jpa에서 bulk insert를 하지 않아야한다.
(성능이 떨어지는 이유는 auto_increment일때 합치기 옵션을 넣어도 적용되지 않기 때문)
대신할 몇가지 방법으로
1. jdbcTemplate로 처리 - 컴파일 체크, 코드와 테이블 불일치 체크 등 타입 세이프한 개발이 어려움
2. Querydsl-SQL 사용

버거롭다 ... 그렇다고 베타DB사용? -> 베타DB칼럼에 반영은 하면는 안되는 상태에서 신규개발은 칼럼변경이 있다면 베타 DB로 개발이 불가능해지는 문제가 있다.
3. EntityQL
JPA Entity를 기반으로 Querydsl-SQL QClass를 만들어주는 프로젝트
-> QClass 문법 형태로 bulk insert가능해짐
문제
1. gradle 5 이상만 사용가능
2. 어노테이션에 (name="")필수 - 테이블, 칼럼 둘다
3. primitive type 사용 불가(int, double 등)
4. 설정이 복잡
5. @Embedded 미지원
6. insert 쿼리를 @Column의 name으로 만들수가 없어서 Mapper를 사용해야하는데 지원해주는 BeanMapper의 경우 컬럼명과 필드명이 일치해야함 만약 언더스코어나 카멜케이싱 등으로 할경우 별도의 mapper를 구현해야 함
개인적인 생각
만약 대량의 insert가 자주 발생한다면 EntityQL사용을 하는것이 맞지만 만약 몇개 되지않거나 쿼리문이 잘 변경되지않는다면 jdbcTemplate로하는것이 좋을거 같다고 생각함
Reference
www.youtube.com/watch?v=zMAX7g6rO_Y&list=WL&index=1&t=392s